从一道DEFCON逆向题来看复用原生函数的几种姿势
在爆破和解混淆时,经常需要复用原有的函数
笔者这里以 DEFCON 2025 - holographic 为例,贴几个常见的做法
题解 #
程序首先读取环境变量 SEED,拿 SEED 的低 24 位播种初始化一个 PRNG,再使用这个 PRNG 洗牌,如果猜对洗过的牌序,输出 /flag
如果没有猜对,程序会给出正确答案,然后重洗
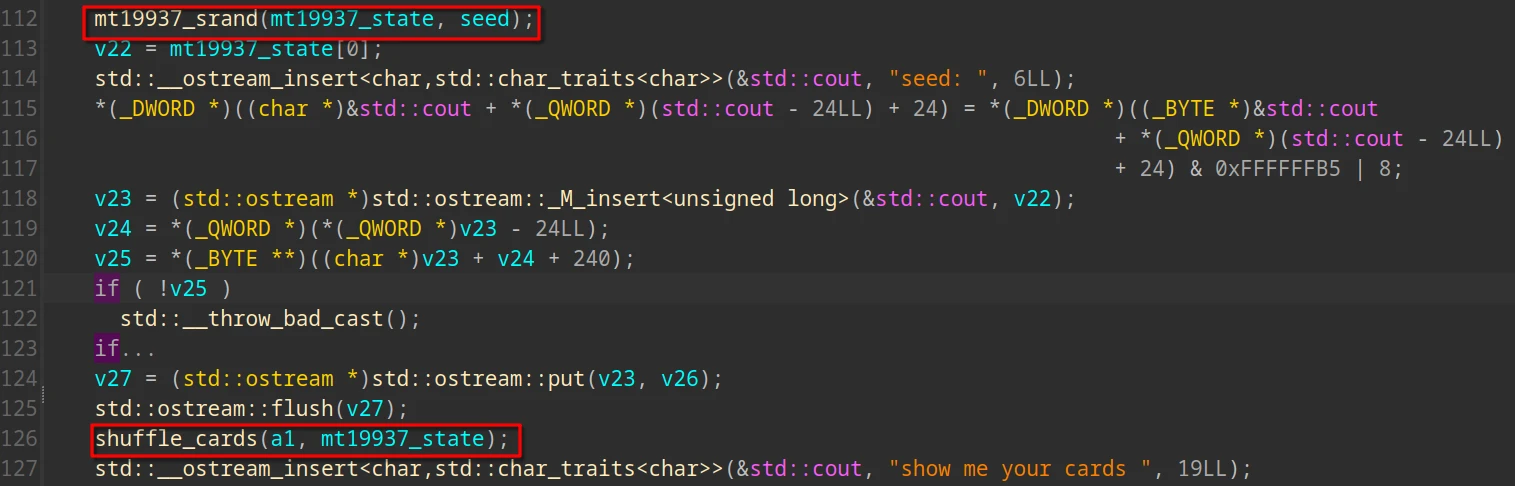
在播种函数中看到常数 624,可以推断出这是 MT19937(64 位)的变体
状态结构体共有 628 个 QWORD,其中第 1 个 QWORD 是使用标准库生成的随机数,第 2 个 QWORD 来自 SEED 的低 24 位,而 main 函数中提示的 seed 提示实际上是 第一个 QWORD,每次洗牌都不一样
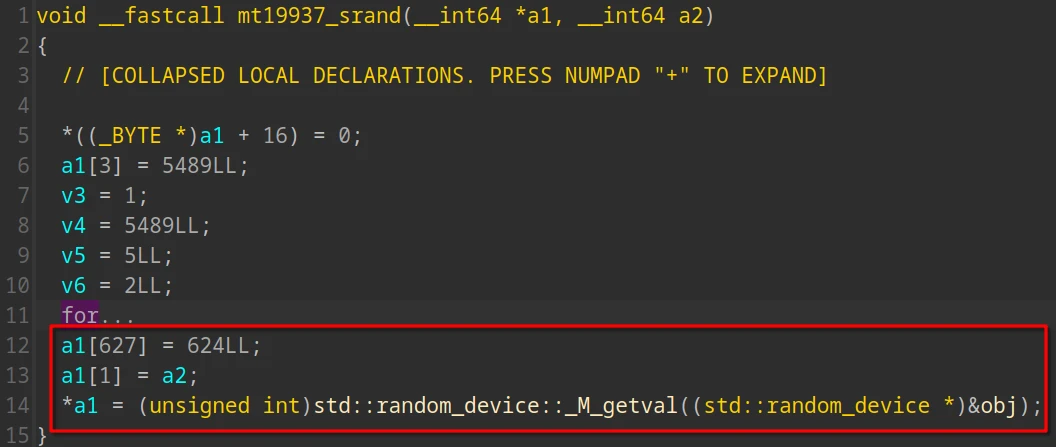
牌张是标准扑克牌,共 52 张
sA s2 s3 s4 s5 s6 s7 s8 s9 sX sJ sQ sK hA h2 h3 h4 h5 h6 h7 h8 h9 hX hJ hQ hK cA c2 c3 c4 c5 c6 c7 c8 c9 cX cJ cQ cK dA d2 d3 d4 d5 d6 d7 d8 d9 dX dJ dQ dK
牌张的内部表示是 0 ~ 51 的 permutation
如图,每次洗牌都是从正序开始而不是继承上一次的顺序,这就给爆破提供了可能性
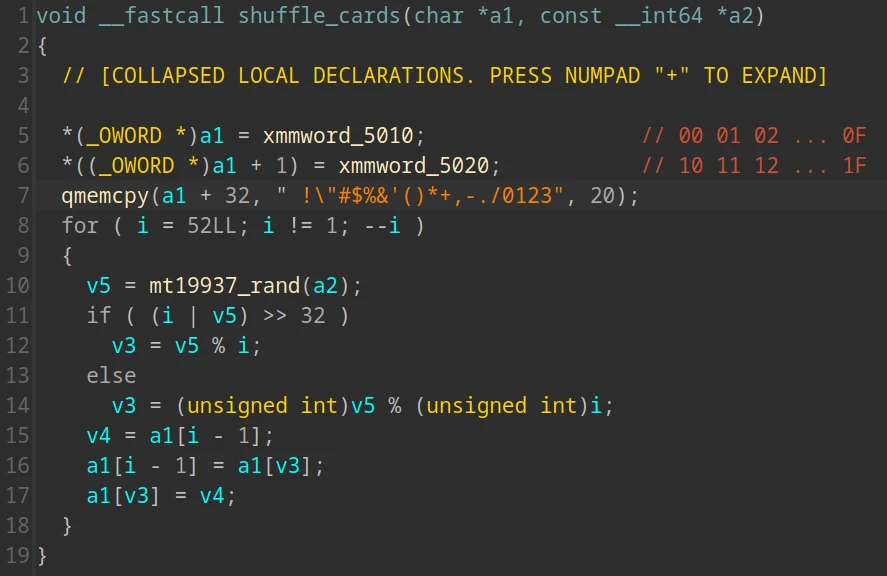
笔者的做法是先随便猜一次,然后爆破出环境变量 SEED 的低 24 位,第二次猜测时就可以通过提示的随机数和 SEED 计算出牌序
爆破和计算牌序都需要用到程序内部魔改的 MT19937,重新逆一遍显然是性价比极低的做法,这也就引出了本文的主题
angr #
angr 提供 Foreign Function Interface (FFI) 功能 (project.factory.callable()),可以以符号化参数执行本地函数,如果提供的是具体输入,就可以得到具体输出
获取 MT19937 播种函数的输出状态后,再拿它去调用洗牌函数即可
为了减少可能发生的错误并避免出现符号化数据,这里需要默认零填充
angr.options.ZERO_FILL_UNCONSTRAINED_MEMORYangr.options.ZERO_FILL_UNCONSTRAINED_REGISTERS
为了让 angr 达到肉眼可见的速度,还需要一些调教:
- 加载 project 时,设置
auto_load_libs=True,避免 angr 使用自己模拟的标准库函数 - 使用
angr.options.unicorn,在具体执行时通过 unicorn 优化 - callable 使用参数
concrete_only=True
import angr
import claripy
import pwn
import tqdm
import time
base_addr = 0x0
heap_addr = 0x100000
project = angr.Project(
"holographic", main_opts={"base_addr": base_addr}, auto_load_libs=True
)
begin_state = project.factory.full_init_state(
add_options={
angr.options.ZERO_FILL_UNCONSTRAINED_MEMORY,
angr.options.ZERO_FILL_UNCONSTRAINED_REGISTERS,
*angr.options.unicorn,
},
remove_options={},
)
p_mt19937 = claripy.BVV(heap_addr, 64)
p_deck = claripy.BVV(heap_addr + 628 * 8, 64)
mt19937_srand = project.factory.callable(
addr=0x2AC0, concrete_only=True, base_state=begin_state
)
shuffle_deck = project.factory.callable(
addr=0x2460, concrete_only=True, base_state=begin_state
)
def check_SEED(target, seed0, SEED):
mt19937_srand(p_mt19937, SEED)
x = mt19937_srand.result_state
x.memory.store(p_mt19937, claripy.BVV(seed0, 64).reversed)
shuffle_deck.set_base_state(x)
shuffle_deck(p_deck, p_mt19937)
x = shuffle_deck.result_state
v = x.memory.load(p_deck, 52).concrete_value.to_bytes(52, byteorder="big")
# print(target)
# print(v)
return target == v
def calc_deck(seed1, SEED):
mt19937_srand(p_mt19937, SEED)
x = mt19937_srand.result_state
x.memory.store(p_mt19937, claripy.BVV(seed1, 64).reversed)
shuffle_deck.set_base_state(x)
shuffle_deck(p_deck, p_mt19937)
x = shuffle_deck.result_state
v = x.memory.load(p_deck, 52).concrete_value.to_bytes(52, byteorder="big")
return v
CARDS = """
sA s2 s3 s4 s5 s6 s7 s8 s9 sX sJ sQ sK hA h2 h3 h4 h5 h6 h7 h8 h9 hX hJ hQ hK cA c2 c3 c4 c5 c6 c7 c8 c9 cX cJ cQ cK dA d2 d3 d4 d5 d6 d7 d8 d9 dX dJ dQ dK
""".strip().split(
" "
)
def cards2bytes(s: str):
s = s.strip().split(" ")
return bytes([CARDS.index(x) for x in s])
def bytes2cards(b: bytes):
return " ".join([CARDS[x] for x in b])
with pwn.process("./holographic", env={"SEED": "114514"}) as r:
seed0 = int(r.recvline_startswith(b"seed: ").decode().split(": ")[1].strip(), 16)
print(seed0)
r.sendline(" ".join(CARDS).encode())
r.recvline()
r.recvline()
c0 = cards2bytes(r.recvline().decode())
print(c0)
start_time = time.time()
print(check_SEED(c0, seed0, 114514))
end_time = time.time()
print(f"execution time: {end_time - start_time:.2f}s")
SEED=114514
seed1 = int(r.recvline_startswith(b"seed: ").decode().split(": ")[1].strip(), 16)
print(seed1)
c1 = bytes2cards(calc_deck(seed1, SEED))
r.sendline(c1.encode())
r.interactive()
在我的机器上,大约 5 秒钟能够跑完一个 check,虽然比优化前提升了一倍,但远远达不到爆破的要求,因此这题需要别的办法
如果结合 mbruteforce 确实可以加速,但 angr 和 pwntools 的日志功能有冲突,没法显示进度
不过 angr 有个好处,如果函数结构比较简单,可以用符号输入将函数“打包”成约束
假设输入为符号 A,输入为符号 B,玩法如下:
def func_packed(A, B, func_args):
S = claripy.Solver()
S.add(A == func_args)
return S.eval(B, 1)[0]
甚至可以用 pickle 把打包的函数(A 和 B)存到硬盘,然后在硬件条件更好的机器中使用 mbruteforce,这样就避免了重复调用 Angr 来符号执行
不过对于这题来说,具体输入都很慢,更不用说用符号输入打包了
Frida #
frida-gum 自带 NativeFunction API,可以通过它来将本地函数导出为 javascript 函数
获取这些函数之后,再搓出需要的功能并暴露 RPC 接口给 frida 控制端
几个容易遗忘的点:
- 函数地址要加上基址,
NativePointer不能直接使用加法,需要使用add()函数 - 调用本地函数时,需要先转换参数类型,例如
uint64(i) - 函数名在 python 端使用下划线模式,会被转换成首字母小写的驼峰模式
import "frida-gum"; // This line is for vscode linting only, please remove it
// if you want to use this script in frida console
// i.e. frida -l
const base = ptr(Process.enumerateModules()[0].base);
const mt19937_srand = new NativeFunction(base.add(0x2ac0), "void", [
"pointer",
"uint64",
]);
const shuffle_deck = new NativeFunction(base.add(0x2460), "void", [
"pointer",
"pointer",
]);
const print_deck = new NativeFunction(base.add(0x2890), "void", ["pointer"]);
rpc.exports = {
findSeed(target, seed0) {
const rng = Memory.alloc(628 * 8);
const deck = Memory.alloc(52);
target = new Uint8Array(target);
send(target);
send(seed0);
for (let i = 0; i < 256 * 256 * 256; i++) {
mt19937_srand(rng, uint64(i));
rng.writeU64(uint64(seed0));
shuffle_deck(deck, rng);
const arr = deck.readByteArray(52);
var eq = new Uint8Array(arr).every(
(value, index) => value === target[index]
);
if (eq) {
return uint64(i);
}
}
},
calc(SEED, seed1) {
const rng = Memory.alloc(628 * 8);
const deck = Memory.alloc(52);
mt19937_srand(rng, uint64(SEED));
rng.writeU64(uint64(seed1));
shuffle_deck(deck, rng);
return deck.readByteArray(52);
},
};
控制端使用 script.export_sync.func() 即可调用函数
一个惨痛的教训是,spawn 函数默认使用 stdio="inherit" 模式,如果 python 脚本结尾忘记调用 kill(pid) 会导致脚本退出而程序不退出,最终程序会和终端抢 stdin,反映到感官上就是大部分输入好像被“卡”掉了
如果想和 spawn 的进程交互,可以给 output 信号添加处理函数来读取 stdout,调用 device.input() 来输入 stdin
爆破的步骤写在了 javascript 里,如果写在控制端可能会带来更多的 RPC,但好处是可以使用多进程来加速
import frida
import pwn
with open("script.js") as fp:
fp.readline()
script_js = fp.read()
device = frida.get_local_device()
def on_output(_pid, _fd, _data: bytes):
lines = _data.decode().split("\n")
for line in lines:
print("> " + line)
# test stdout
device.on("output", on_output)
pid = device.spawn("holographic", env={"SEED": "114514"}, stdio="pipe")
session = device.attach(pid)
script = session.create_script(script_js)
script.on("message", lambda _msg, _date: print(_msg))
script.load()
device.resume(pid)
CARDS = """
sA s2 s3 s4 s5 s6 s7 s8 s9 sX sJ sQ sK hA h2 h3 h4 h5 h6 h7 h8 h9 hX hJ hQ hK cA c2 c3 c4 c5 c6 c7 c8 c9 cX cJ cQ cK dA d2 d3 d4 d5 d6 d7 d8 d9 dX dJ dQ dK
""".strip().split(" ")
# test stdin
device.input(target=pid, data=" ".join(CARDS).encode() + b"\n")
def cards2bytes(s: str):
s = s.strip().split(" ")
return bytes([CARDS.index(x) for x in s])
def bytes2cards(b: bytes):
return " ".join([CARDS[x] for x in b])
with pwn.process("./holographic", env={"SEED": "114514"}) as r:
seed0 = int(r.recvline_startswith(b"seed: ").decode().split(": ")[1].strip(), 16)
print(seed0)
r.sendline(" ".join(CARDS).encode())
r.recvline()
r.recvline()
c0 = cards2bytes(r.recvline().decode())
print(c0)
SEED = int(script.exports_sync.find_seed(list(c0), seed0))
print(SEED)
seed1 = int(r.recvline_startswith(b"seed: ").decode().split(": ")[1].strip(), 16)
print(seed1)
c1 = bytes2cards(script.exports_sync.calc(SEED, seed1))
r.sendline(c1.encode())
r.interactive()
input()
session.detach()
device.kill(pid)
frida 的优点是原生调用,函数本身执行速度快,缺点是 RPC 和拷贝执行会带来一定的开销
Unicorn Engine #
angr 的 concrete 加速本质上也是 unicorn 执行,直接用 unicorn 加载程序的字节码也是可行的,这样就避免了 RPC
加载程序主要有 4 步:内存映射、重定位、解析外部符号、转到入口点
由于 x64 存在 RIP 相对寻址功能,代码段中现在很少出现重定位,ELF 中的重定位大多是用于 .init_array 这类在数据段中引用代码段内地址的情况,不影响复用函数;解析外部符号涉及到动态库加载,但对于解题脚本来说在 .plt 下个钩子就好了,因此笔者这里只做了内存映射
(写到这才发现,unidbg 不就是干这个的吗 -_-)
import unicorn as uc
import unicorn.x86_const as ucc
from elftools.elf.elffile import ELFFile
import struct
with open("holographic", "rb") as fp:
elf = ELFFile(fp)
arch = uc.UC_ARCH_X86
mode = uc.UC_MODE_64
mu = uc.Uc(arch, mode)
for segment in elf.iter_segments():
if segment.header.p_type == "PT_LOAD":
vaddr = segment.header.p_vaddr
mem_size = segment.header.p_memsz
file_size = segment.header.p_filesz
align = segment.header.p_align
# memory alignment
mem_begin = vaddr & ~(align - 1)
mem_end = (vaddr + mem_size + align - 1) & ~(align - 1)
map_addr = mem_begin
map_size = mem_end - mem_begin
mu.mem_map(map_addr, map_size, uc.UC_PROT_ALL)
data = segment.data()
mu.mem_write(vaddr, data)
if mem_size > file_size:
bss_start = vaddr + file_size
bss_size = mem_size - file_size
mu.mem_write(bss_start, b"\x00" * bss_size)
print(f"Loaded segment: 0x{vaddr:016x}-0x{vaddr+mem_size:016x}")
stack_base = 0x80000000
stack_size = 0x10000
mu.mem_map(stack_base - stack_size, stack_size, uc.UC_PROT_READ | uc.UC_PROT_WRITE)
rsp = stack_base - 0x100
mu.reg_write(ucc.UC_X86_REG_RSP, rsp)
print(f"RSP: 0x{rsp:016x}")
entry = elf.header.e_entry
print(f"ELF entry point: 0x{entry:016x}")
heap_base = 0x70000000
heap_size = 0x10000
mu.mem_map(heap_base, heap_size, uc.UC_PROT_READ | uc.UC_PROT_WRITE)
print(f"heap at: 0x{heap_base:016x}")
_START = 0x2340
image_base = entry - _START
def fake_ret(_mu: uc.Uc, ret_val=None):
if ret_val is not None:
_mu.reg_write(ucc.UC_X86_REG_RAX, ret_val)
rsp = _mu.reg_read(ucc.UC_X86_REG_RSP)
ret_addr = struct.unpack("<Q", _mu.mem_read(rsp, 8))[0]
_mu.reg_write(ucc.UC_X86_REG_RSP, rsp + 8)
#print(f"returning to 0x{ret_addr:016x}")
_mu.reg_write(ucc.UC_X86_REG_RIP, ret_addr)
random_device_addr = heap_base + 0x0
def set_random_device(_mu: uc.Uc, state):
global random_device_addr
_mu.mem_write(random_device_addr, struct.pack("<Q", state))
def plt_random_device(_mu: uc.Uc, address, size, user_data):
global random_device_addr
#print(f"libc random_device called at 0x{address:x}, size: {size}")
state = struct.unpack("<Q", _mu.mem_read(random_device_addr, 8))[0]
fake_ret(_mu, state)
_RANDOM_DEVICE = 0x21E0 + image_base
mu.hook_add(
uc.UC_HOOK_CODE, plt_random_device, begin=_RANDOM_DEVICE, end=_RANDOM_DEVICE + 6
)
def plt_memset(_mu: uc.Uc, address, size, user_data):
#print(f"libc memset called at 0x{address:x}, size: {size}")
s = _mu.reg_read(ucc.UC_X86_REG_RDI)
c = _mu.reg_read(ucc.UC_X86_REG_SIL)
n = _mu.reg_read(ucc.UC_X86_REG_RDX)
_mu.mem_write(s, bytes([c]) * n)
fake_ret(_mu)
_MEMSET = 0x20E0 + image_base
mu.hook_add(uc.UC_HOOK_CODE, plt_memset, begin=_MEMSET, end=_MEMSET + 6)
def plt_memmov(_mu: uc.Uc, address, size, user_data):
#print(f"libc memmov called at 0x{address:x}, size: {size}")
dest = _mu.reg_read(ucc.UC_X86_REG_RDI)
src = _mu.reg_read(ucc.UC_X86_REG_RSI)
n = _mu.reg_read(ucc.UC_X86_REG_RDX)
data = _mu.mem_read(src, n)
_mu.mem_write(dest, data)
fake_ret(_mu)
_MEMMOV = 0x2220 + image_base
mu.hook_add(uc.UC_HOOK_CODE, plt_memmov, begin=_MEMMOV, end=_MEMMOV + 6)
heap_ptr = heap_base + 0x8000
def reset_heap(_mu):
global heap_ptr
heap_ptr = heap_base + 0x8000
def plt_new(_mu: uc.Uc, address, size, user_data):
#print(f"libc new called at 0x{address:x}, size: {size}")
global heap_ptr
n = _mu.reg_read(ucc.UC_X86_REG_RDI)
buffer = heap_ptr
heap_ptr += n + (63 - ((n - 1) % 64))
fake_ret(_mu, buffer)
_NEW = 0x2170 + image_base
mu.hook_add(uc.UC_HOOK_CODE, plt_new, begin=_NEW, end=_NEW)
def plt_delete(_mu: uc.Uc, address, size, user_data):
#print(f"libc delete called at 0x{address:x}, size: {size}")
global heap_ptr
fake_ret(_mu)
_DELETE = 0x2160 + image_base
mu.hook_add(uc.UC_HOOK_CODE, plt_delete, begin=_DELETE, end=_DELETE)
mt19937_start = 0x2AC0 + image_base
mt19937_end = 0x2BA2 + image_base
shuffle_deck_start = 0x2460 + image_base
shuffle_deck_end = 0x24E2 + image_base
def native_mt19937(p_mt19937, SEED):
try:
mu.reg_write(ucc.UC_X86_REG_RDI, p_mt19937)
mu.reg_write(ucc.UC_X86_REG_RSI, SEED)
mu.emu_start(mt19937_start, mt19937_end, timeout=-1)
except uc.UcError as e:
print(f"Unicorn error: {e}")
rip = mu.reg_read(ucc.UC_X86_REG_RIP)
print(f"RIP at error: 0x{rip:016x}")
mt19937 = mu.mem_read(p_mt19937, 628 * 8)
return mt19937
def native_shuffle_deck(p_deck, p_mt19937):
try:
mu.reg_write(ucc.UC_X86_REG_RDI, p_deck)
mu.reg_write(ucc.UC_X86_REG_RSI, p_mt19937)
mu.emu_start(shuffle_deck_start, shuffle_deck_end, timeout=-1)
except uc.UcError as e:
print(f"Unicorn error: {e}")
rsp = mu.reg_read(ucc.UC_X86_REG_RSP)
ret_addr = struct.unpack("<Q", mu.mem_read(rsp, 8))[0]
print(f"returning to 0x{ret_addr:016x}")
rip = mu.reg_read(ucc.UC_X86_REG_RIP)
print(f"RIP at error: 0x{rip:016x}")
deck = mu.mem_read(p_deck, 52)
return deck
def checkSEED(target, seed0, SEED):
set_random_device(mu, seed0)
reset_heap(mu)
p_mt19937 = heap_base + 0x1000
p_deck = heap_base + 0x3000
mt19937 = native_mt19937(p_mt19937, SEED)
assert struct.unpack("<Q", mt19937[627*8:])[0] == 624
deck = native_shuffle_deck(p_deck, p_mt19937)
return target == deck
def calcDeck(seed1, SEED):
set_random_device(mu, seed1)
reset_heap(mu)
p_mt19937 = heap_base + 0x1000
p_deck = heap_base + 0x3000
mt19937 = native_mt19937(p_mt19937, SEED)
assert struct.unpack("<Q", mt19937[627*8:])[0] == 624
deck = native_shuffle_deck(p_deck, p_mt19937)
return deck
import pwn
import tqdm
CARDS = """
sA s2 s3 s4 s5 s6 s7 s8 s9 sX sJ sQ sK hA h2 h3 h4 h5 h6 h7 h8 h9 hX hJ hQ hK cA c2 c3 c4 c5 c6 c7 c8 c9 cX cJ cQ cK dA d2 d3 d4 d5 d6 d7 d8 d9 dX dJ dQ dK
""".strip().split(" ")
def cards2bytes(s: str):
s = s.strip().split(" ")
return bytes([CARDS.index(x) for x in s])
def bytes2cards(b: bytes):
return " ".join([CARDS[x] for x in b])
with pwn.process("./holographic", env={"SEED": "114514"}) as r:
seed0 = int(r.recvline_startswith(b"seed: ").decode().split(": ")[1].strip(), 16)
print(seed0)
r.sendline(" ".join(CARDS).encode())
r.recvline()
r.recvline()
c0 = cards2bytes(r.recvline().decode())
print(c0)
SEED = 0
for i in tqdm.tqdm(range(256 * 256 * 256)):
if checkSEED(c0, seed0, i) is True:
SEED = i
break
seed1 = int(r.recvline_startswith(b"seed: ").decode().split(": ")[1].strip(), 16)
print(seed1)
c1 = bytes2cards(calcDeck(seed1, SEED))
r.sendline(c1.encode())
r.interactive()
初始化时,需要找到类型为 PT_LOAD 的段,拷贝到模拟内存中,还需注意对齐和填充
栈和堆随便选一大块内存映射就好
从 IDA Call Graph 可以看到,两个函数涉及到的 libc API 只有 random_device, memmov, memset, operator new 和 operator delete,笔者这里全部实现了一遍(实现得很烂)
该方法的优点是无需 RPC,也适合多进程爆破,缺点则是实现起来比较麻烦,而且很容易出错
从效率上来说,虽然该方法采用模拟执行,但只要本机和程序的架构相同,经过 unicorn 的优化应该是能够达到原生速度的,虽然没有测过,但我猜和 frida 差不多快
libdebug #
完全避免了模拟执行和 RPC 且能达到原生速度的办法
(GDB 脚本好像也行?)
WIP