刷题-starCTF2022
没有参加,当做刷题做的,因为有官方解,就当是复现吧
simple_fs #
I implemented a very simple file system and buried my flag in it.
The image file are initiated as follows:
./simplefs image.flag 500
simplefs> format
simplefs> mount
simplefs> plantflag
simplefs> exit
And you cold run "help" to explore other commands.
需要关注的部分主要就是 plantflag 命令(搜索 flag 字符串即可定位)
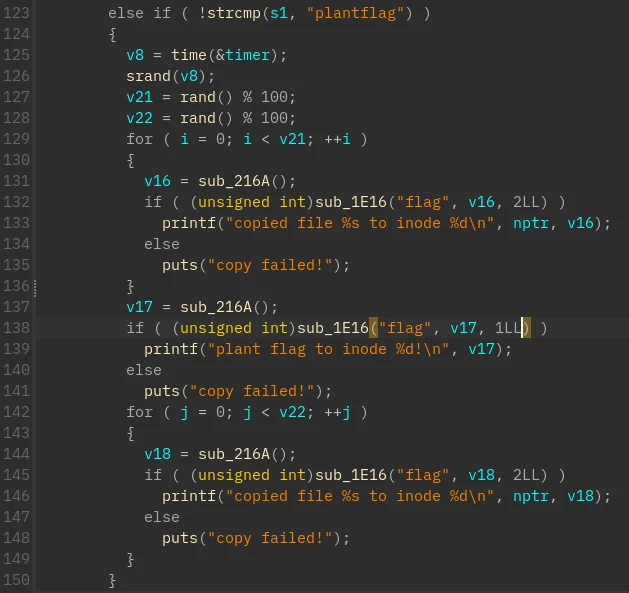
sub_216A 由内部字串得为 create_inode 函数
sub_1E16 同理,为 fs_write 函数
fs_write 有两种功能
- a3=1 对应 sub_21B2 是将数据以某个 uint 加密
- a3=2 对应 sub_2305 是写入纯粹随机数
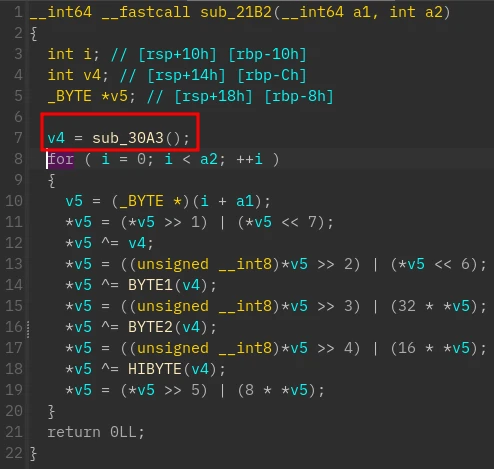
关键的函数是 sub_30A3,它调用了 sub_3D23(0, v1)
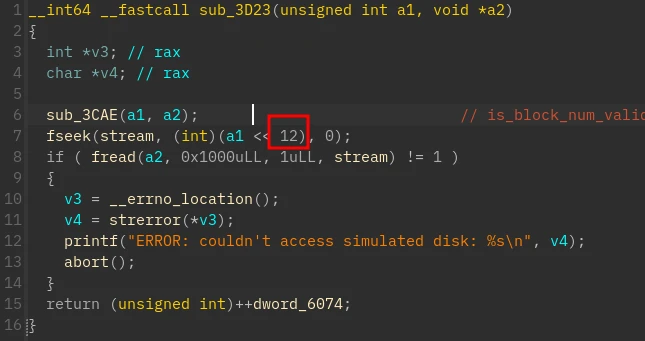
从报错字符串可以看出 sub_3CAE 只是检查块号是否合理
而第 7 行的 fseek 泄漏了块长度为 4096
因此 sub_30A3 里 v1 的长度需要手动修改
该函数即从第 0 号块读取第 4 个 uint(它是 0xdeedbeef)
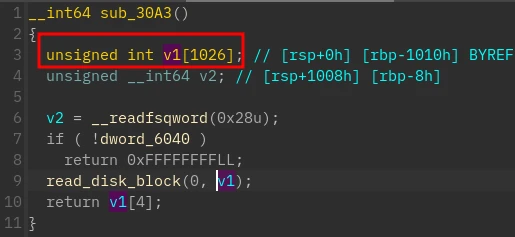
考虑将所有的块全部转储并解密,随机生成的块会成为乱码,而包含 flag 的块将会显示可读字符
payload = []
payload.append('mount\n')
for i in range(79):
payload.append(f'copyout {i} dump{i}\n')
payload.append('quit\n')
p = subprocess.Popen(["./simplefs", "image.flag", "500"], stdin=subprocess.PIPE, stdout=subprocess.DEVNULL)
p.stdin.write(''.join(payload).encode())
#*CTF{Gwed9VQpM4Lanf0kEj1oFJR6}
Jump #
静态链接的程序
readelf -p .comment Jump
GCC: (Ubuntu 9.4.0-1ubuntu1~20.04) 9.4.0
在 IDA 中导入签名来恢复库函数
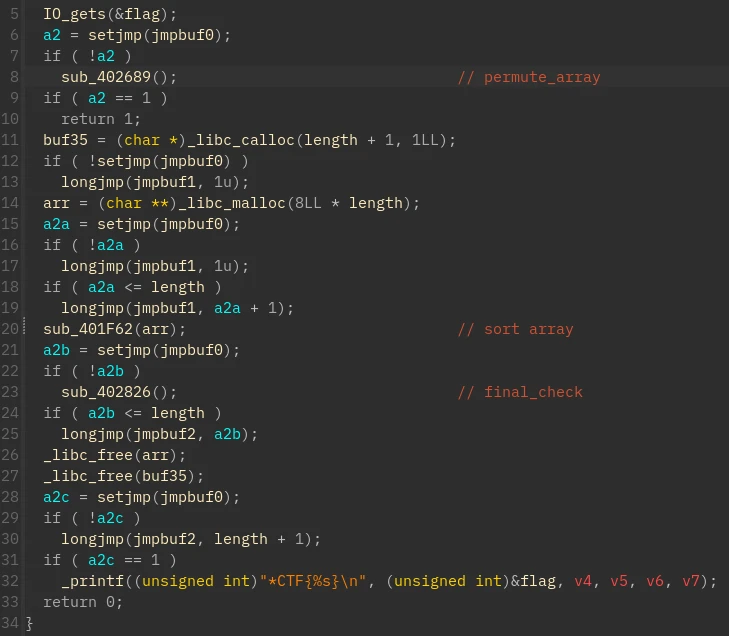
可以看到 main 函数用 setjmp 和 longjmp 重构了控制流
sub_402689 的功能是将 flag 的首尾加上 0x02 和 0x03 并且生成一组 flag 的变换(在下标 i 处交换前后两段)
def permute_array(x):
flag = b'\x02' + x + b'\x03'
arr = [flag[i:] + flag[:i] for i in range(34)]
return arr
sub_402826 是最终比较,将会选取上面字串数组中每个字串的最后一个字符拼接而成最终字符串
def final_check(arr):
secret = b'\x03jmGn_=uaSZLvN4wFxE6R+p\x02D2qV1CBTck'
cipher = bytes(arr[i][33] for i in range(34))
return cipher == secret
sub_402826 是一个快排,实际上由于 secret 字符各不相同,只会比较第一个字节
也就是说,通过字符 x 在 secret 中的位置可以得到 flag 中 x 后一个字符在排序后的位置,而将要输入的 flag 是 secret 的变异,经过排序后,arr 中所有字串的首字符组成的列也是固定的,即 secret 中所有字符的排序
这样就可以知道 flag 中每个字符的后一个字符,也就知道了 flag
secret = b"\x03jmGn_=uaSZLvN4wFxE6R+p\x02D2qV1CBTck"
heads = [i for i in secret]
heads.sort()
tails = secret
nextof = {}
for ch in range(34):
nextof[tails[ch]] = heads[ch]
flag = []
ch = 2
while True:
ch = nextof[ch]
if ch == 3:
break
flag.append(ch)
flag = bytes(flag).decode()
print(flag)
# cwNG1paBu=6Vn2kxSCqm+_4LETvFRZDj
NaCl #
Do you know Google's Native Client? But not Google's NaCl, This is eric's NaCl!!!
也是静态链接的程序,同上题导入符号表
main 函数调用了一个位于 SFI 节的函数,该函数被混淆,无法 F5
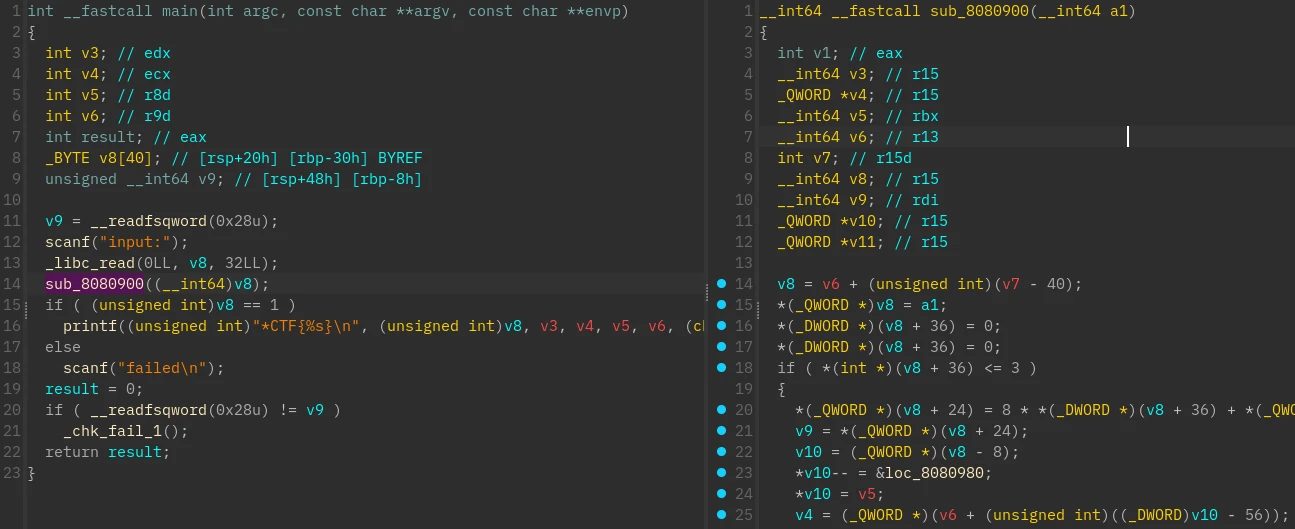
进一步检查得知,该程序的逻辑就在 SFI 节中,另有一个 SFI_data 节为其提供数据,将这两个被混淆的节转储
objcopy -j SFI -O binary NaCl SFI.bin
objcopy -j SFI_data -O binary NaCl SFI_data.bin
可以用 Unicorn 打 log 观察混淆的模式
from unicorn import *
from unicorn.x86_const import *
from capstone import *
md = Cs(CS_ARCH_X86, CS_MODE_64)
with open("SFI.bin", "rb") as fp:
text = fp.read()
with open("SFI_data.bin", "rb") as fp:
data = fp.read()
flag = b"0123456789ABCDEF"
mu = Uc(UC_ARCH_X86, UC_MODE_64)
base_addr = 0x8000000
seg_size = 0x1000000
stack_addr = 0x7000000
text_addr = 0x7FEC0 + base_addr
data_addr = 0xAFB40 + base_addr
start_addr = 0x80900 + base_addr
end_addr = 0x80AD1 + base_addr
mu.mem_map(base_addr, seg_size)
mu.mem_map(stack_addr, seg_size)
mu.mem_write(text_addr, text)
mu.mem_write(data_addr, data)
mu.mem_write(stack_addr, flag)
mu.reg_write(UC_X86_REG_R15, stack_addr + seg_size - 0x100)
mu.reg_write(UC_X86_REG_RDI, stack_addr)
def hook_code(mu, address, size, user_data):
global md
if mu.reg_read(UC_X86_REG_RIP) != address:
print(mu.reg_read(UC_X86_REG_RIP))
code = mu.mem_read(address, size)
insns = list(md.disasm(bytes(code), address, count=1))
if len(insns) == 0:
raise Exception(f"cant disasm insn at {address}")
insn = insns[0]
address = insn.address
size = insn.size
mnemonic = insn.mnemonic
op_str = insn.op_str
print("%016x:\t%s\t%s" % (address, mnemonic, op_str))
mu.hook_add(UC_HOOK_CODE, hook_code)
try:
mu.emu_start(start_addr, end_addr)
except Exception as e:
print(f"{hex(mu.reg_read(UC_X86_REG_RIP))}:\t{e}")
可以看出目标使用 r15 代替了 rsp,r13 代替了 ds,并且改写了隐性使用 rsp 的指令如 call, ret, push, pop 等
call 指令
0000000008080960: lea r15, [r15 - 8]
0000000008080964: lea r12, [rip + 0x15]
000000000808096b: mov qword ptr [r15], r12
000000000808096e: jmp 0x8080720
ret 指令
00000000080802e0: lea r15, [r15 + 8]
00000000080802e4: mov edi, dword ptr [r15 - 8]
00000000080802e8: and edi, 0xffffffe0
00000000080802eb: lea rdi, [r13 + rdi]
00000000080802f0: jmp rdi
笔者的做法是将 call 和 ret 全部还原
call 指令的 jmp 后面还有一小段随机长度的 padding,这是为了随机化第二个 lea 中 rip 结合的偏移,而 ret 指令中没有变化的东西
接下来还需要
- 将 r15 和 r15d 出现的地方均换成 rsp,如
sub r15d 0x30 -> sub rsp, 0x30 - 将和 r13 结合的内存寻址改换为基于 ds 的寻址,如
[r13 + rax] -> ds:[rax]
实现上采用一小段滑动窗口,并在窗口中匹配多条指令组成的正则 pattern
窗口左侧每轮都将前进匹配到的条数,默认情况只处理窗口里第一条指令(修改 r15 和 r13)
from capstone import *
from keystone import *
import re
with open("SFI.bin", "rb") as fp:
text = fp.read()
with open("SFI_data.bin", "rb") as fp:
data = fp.read()
recovered = bytearray()
base_addr = 0x8000000
seg_size = 0x1000000
text_addr = 0x7FEC0 + base_addr
data_addr = 0xAFB40 + base_addr
start_addr = 0x80900 + base_addr
md = Cs(CS_ARCH_X86, CS_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
insns = list(md.disasm(text, text_addr))
addr_map = {}
rev_addr_map = {}
CALL = [
[r"lea", r"r15, \[r15 - 8\]"],
[r"lea", r"r12, \[rip \+ ([0-9a-zA-Z]+)\]"],
[r"mov", r"qword ptr \[r15\], r12"],
[r"jmp", r"([0-9a-zA-Z]+)"],
]
RET = [
[r"lea", r"r15, \[r15 \+ 8\]"],
[r"mov", r"edi, dword ptr \[r15 - 8\]"],
[r"and", r"edi, 0xffffffe0"],
[r"lea", r"rdi, \[r13 \+ rdi\]"],
[r"jmp", r"rdi"],
]
def snippet_match(pats, insns, left, right):
if right - left < len(pats):
return None
args = []
for i in range(len(pats)):
insn = insns[left + i]
pat = pats[i]
if insn.mnemonic != pat[0]:
return None
match = re.fullmatch(pat[1], insn.op_str)
if match is None:
return None
args.extend(match.groups())
return args
# patch
left = 0
right = 0
while left < len(insns):
while left + 10 > right and right < len(insns):
right += 1
va = insns[left].address
new_va = len(recovered) + text_addr
addr_map[va] = new_va
rev_addr_map[new_va] = va
# is call?
args = snippet_match(CALL, insns, left, right)
if args is not None:
left += len(CALL)
dest = int(args[1], 16)
insn_data = ks.asm("%s\t%s" % ("call", hex(dest)), va)[0]
recovered.extend(insn_data)
continue
# is ret?
args = snippet_match(RET, insns, left, right)
if args is not None:
left += len(RET)
insn_data = ks.asm("ret", va)[0]
recovered.extend(insn_data)
continue
# default behavior: recover rsp and ss
curr = insns[left]
left += 1
mnemonic = curr.mnemonic
if mnemonic == "nop":
continue
elif mnemonic == "mov" or mnemonic == "xchg":
lop, rop = curr.op_str.split(", ") # junk: mov eax, eax
if lop == rop:
continue
op_str = re.sub(r"\[r13 \+ ", "ds:[", curr.op_str)
op_str = re.sub(r"r15d?", "rsp", op_str)
if op_str != curr.op_str:
insn_data = ks.asm("%s\t%s" % (mnemonic, op_str), va)[0]
recovered.extend(insn_data)
else:
recovered.extend(curr.bytes)
实践中发现部分指令替换 r15 为 rsp 后长度有所增加,故开辟一个新的缓冲区而不是在原有缓冲区上修补
这样也有利于抛弃掉多字节的 nop,和一些干扰 IDA 识别指针的指令如 mov eax, eax,缺点是需要进行重定位
重定位的实现依赖于两个地址映射表,将原始地址双向映射到新地址
遇到需要重定位的条目时,先通过新地址到原始地址的映射计算出原始的引用,再通过原始地址到新地址的映射计算出新的偏移,公式如下:
old_va = rev_addr_map[va]old_dest = size + old_va + old_reladdr_map[old_dest] = dest = size + va + rel
写回 recovered.bin 时需要维护 text 和 data 的偏移关系
# relocate
for insn in md.disasm(recovered, text_addr):
va = insn.address
ra = va - text_addr
size = insn.size
mnemonic = insn.mnemonic
op_str = insn.op_str
# jmp/jcc or call
if mnemonic.startswith("j") or mnemonic == "call":
print("%016x:\t%s\t%s" % (va, mnemonic, op_str))
fake_dest = int(op_str, 16)
dest = fake_dest - va + rev_addr_map[va]
true_dest = addr_map[dest] if dest in addr_map else dest
new_op_str = hex(true_dest)
print(f"cooked new op_str {new_op_str}")
insn_data = ks.asm("%s\t%s" % (mnemonic, new_op_str), va)[0]
insn_data.extend([0x90] * (size - len(insn_data)))
recovered[ra : ra + size] = insn_data
continue
# [rip + rel]
match = re.search(r"rip \+ ([0-9a-zA-Z]+)", op_str)
if match is not None:
print("%016x:\t%s\t%s" % (va, mnemonic, op_str))
fake_rel = match.groups()[0]
if fake_rel.startswith("0x"):
fake_rel = int(fake_rel, 16)
else:
fake_rel = int(fake_rel)
dest = fake_rel + (rev_addr_map[va] + size)
true_dest = addr_map[dest] if dest in addr_map else dest
true_rel = true_dest - (va + size)
new_op_str = re.sub(r"rip \+ ([0-9a-zA-Z]+)", f"rip + {hex(true_rel)}", op_str)
print(f"cooked new op_str {new_op_str}")
insn_data = ks.asm("%s\t%s" % (mnemonic, new_op_str), va)[0]
insn_data.extend([0x90] * (size - len(insn_data)))
recovered[ra : ra + size] = insn_data
continue
# default behavior: do nothing
pass
with open("recovered.bin", "wb") as fp:
fp.write(recovered)
assert len(recovered) <= data_addr - text_addr
fp.write(b"\x00" * (data_addr - text_addr - len(recovered)))
fp.write(data)
print(f"new entry at sub_{hex(addr_map[start_addr])[2:]}")
# new entry at sub_8080457
打开 recovered.bin,选择重定位段到 0x807fec0,很清晰的逻辑
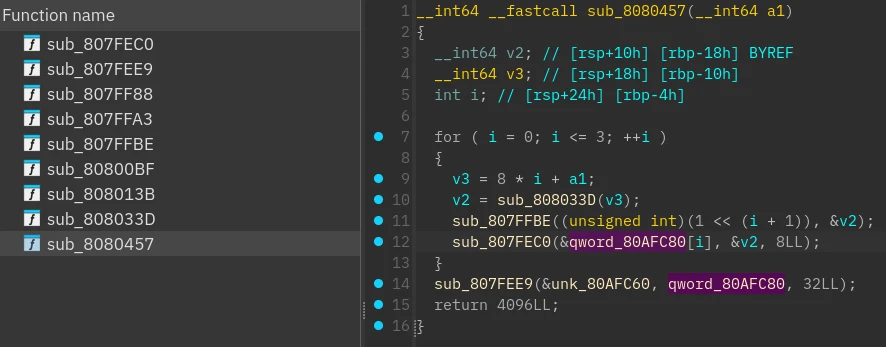
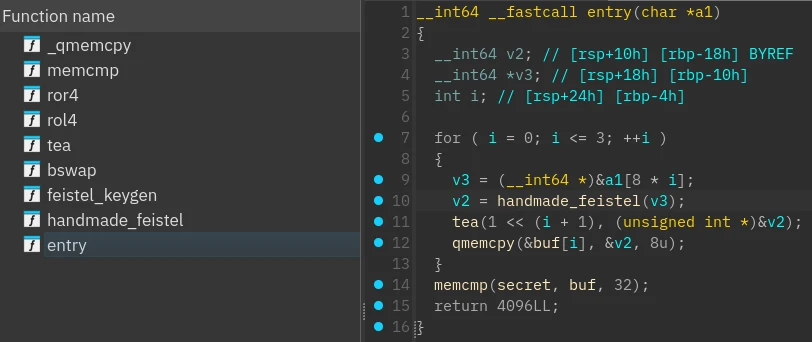
第 10 行手搓 feistel 的解密代码:
def keygen():
v1 = 0x67452301EFCDAB89
v2 = 0x98BADCFE
key = [
byte_swap_ulong(tea_key[1]),
byte_swap_ulong(tea_key[0]),
byte_swap_ulong(tea_key[3]),
byte_swap_ulong(tea_key[2]),
]
for i in range(4, 44):
x = key[i - 4] ^ (v1 & 1) ^ v2
y = key[i - 3] ^ ror(key[i - 1], 3) ^ x
z = ror(key[i - 1], 4) ^ y
key.append(ror(key[i - 3], 1) ^ z)
v1 >>= 1
return key
def dec_feistel(val):
feistel_key = keygen()
low = val >> 32
high = val & MASK
for i in range(43, -1, -1):
a = high
b = low ^ (rol(a, 8) & rol(a, 1)) ^ rol(a, 2) ^ feistel_key[i]
low = a
high = b
high = byte_swap_ulong(high)
low = byte_swap_ulong(low)
return (high << 32) | low
*CTF{mM7pJIobsCTQPO6R0g-L8kFExhYuivBN}
proto-re #
I think this task should belong to RE category?
WIP